
How to Run LLMs Locally and Why It's Becoming More Relevant
Dependencies Are Vulnerabilities, Quality Gaps Are Narrowing, Asymptotic Convergence, Smaller Specialist Models, DIY

🤖 TL;DR: Smaller open-source models are becoming increasingly competitive with closed-source alternatives. Using them locally gives you complete control over your data and infrastructure. This blog shows you exactly how to deploy them on your own hardware and why it is important.
Dependencies Are Vulnerabilities
Your business relies on external AI APIs. Tomorrow, new export restrictions could cut off access to your region. Your AI-powered fraud detection, customer service, and analytics systems stop working. Your operations halt.
A couple of examples that highlight this:
Geopolitical tensions drive semiconductor export controls restricting AI chip access globally
Closed-source cloud services (OpenAI, Anthropic via AWS/Google/Azure) remain subject to government oversight and potential restrictions
Data sovereignty concerns make GDPR compliance with closed-source cloud AI legally problematic for European businesses
Apple's reported $6.2B interest in Mistral AI (recent reports) signals another EU AI asset potentially moving to US control
Solution: Run open-source AI models on your own infrastructure with complete control over your data and operations.
Quality Gaps Are Narrowing
Let's be honest: closed-source models from the leading foundational model providers still generally outperform their open-source counterparts, especially the smaller ones. But here's what's changing rapidly:
Stanford's 2025 AI Index shows that in January 2024, the top U.S. model outperformed the best Chinese model by 9.26 percent; by February 2025, this gap has narrowed to just 1.70 percent. Similar convergence is happening between closed and open-source models.
The same report reveals that many benchmarks we use to gauge AI systems are becoming "saturated"—AI systems get such high scores that the benchmarks are no longer useful for differentiation. This suggests we're approaching fundamental performance limits across all model types.
Asymptotic Convergence
My thesis: Model quality will asymptotically converge. Eventually, there won't be meaningful differences between closed-source and open-source models of similar scale. Therefore, most value capture will shift to the application layer - how you deploy, optimize, and integrate AI into your specific workflows and business processes. Why?
Architectural innovations spread rapidly - Research gets published, techniques get adopted
Training data is becoming commoditized - Similar datasets are available to all players
Fundamental physics limits - There are computational and data efficiency ceilings
Talent mobility - Researchers move between companies, knowledge transfers
We're seeing early signs of this convergence already.
Smaller Specialist Models
While everyone obsesses over larger general models, I find it highly interesting to look at smaller specialist models. In some domains, they even outperform general monolithic bigger models.
Looking in the medical AI corner, an interesting one I found is the Diabetica-7B model, which scored 87.2% accuracy on diabetes queries—beating both GPT-4 and Claude-3.5. That's a 7B model which can runs easily on the latest macbooks.
Improved small model performed can also be found in the coding corner. MIT researchers in 2025 developed an architecture that enables small, open-source models to outperform specialized commercial closed-source models more than double their size in Python code generation. DeepSeek-R1, an open-source reasoning model, excels at complex reasoning and mathematical problem-solving through self-verification techniques.
This pattern can be found in more domains. Financial services use specialized fraud detection models that crush general-purpose ones. JetBrains talks about "focal models" under 10 billion parameters that deliver better domain performance at a fraction of the cost.
The efficiency gains are appearing across general-purpose models too. Microsoft's Phi-3.5 series includes models like Phi-3.5-mini-instruct with just 3.82 billion parameters that are doing pretty well in language, reasoning, coding, and math. Gemma 2 comes in 9 billion and 27 billion parameter versions that can run locally on personal computers. StableLM 2 offers a 1.6 billion parameter model for specific, narrow tasks with faster processing, while their 12B model provides more capability without massive resource requirements. Qwen2.5 supports 29 different languages and scales up to 72 billion parameters for code generation and mathematical problem-solving.
Therefore: Get familiar with running Models in your own infra
Enough talking. Running models locally can be super straightforward. I’m on a macbook pro with an M4 chip and 24gb of RAM. For this tutorial, I’m using Ollama. While Ollama provides the simplest path to local deployment, you have several other options: you can run models directly using Python frameworks like Transformers and llama.cpp for more control, deploy via Docker containers for scalable production environments, or use specialized platforms for high-performance inference on GPUs.
Step 1: Install Ollama
Head to the Ollama Download page and follow the instructions for your platform—Mac, Linux, or Windows. Ollama supports GPU acceleration on Nvidia, AMD, and Apple Metal, so it'll harness whatever hardware you've got.
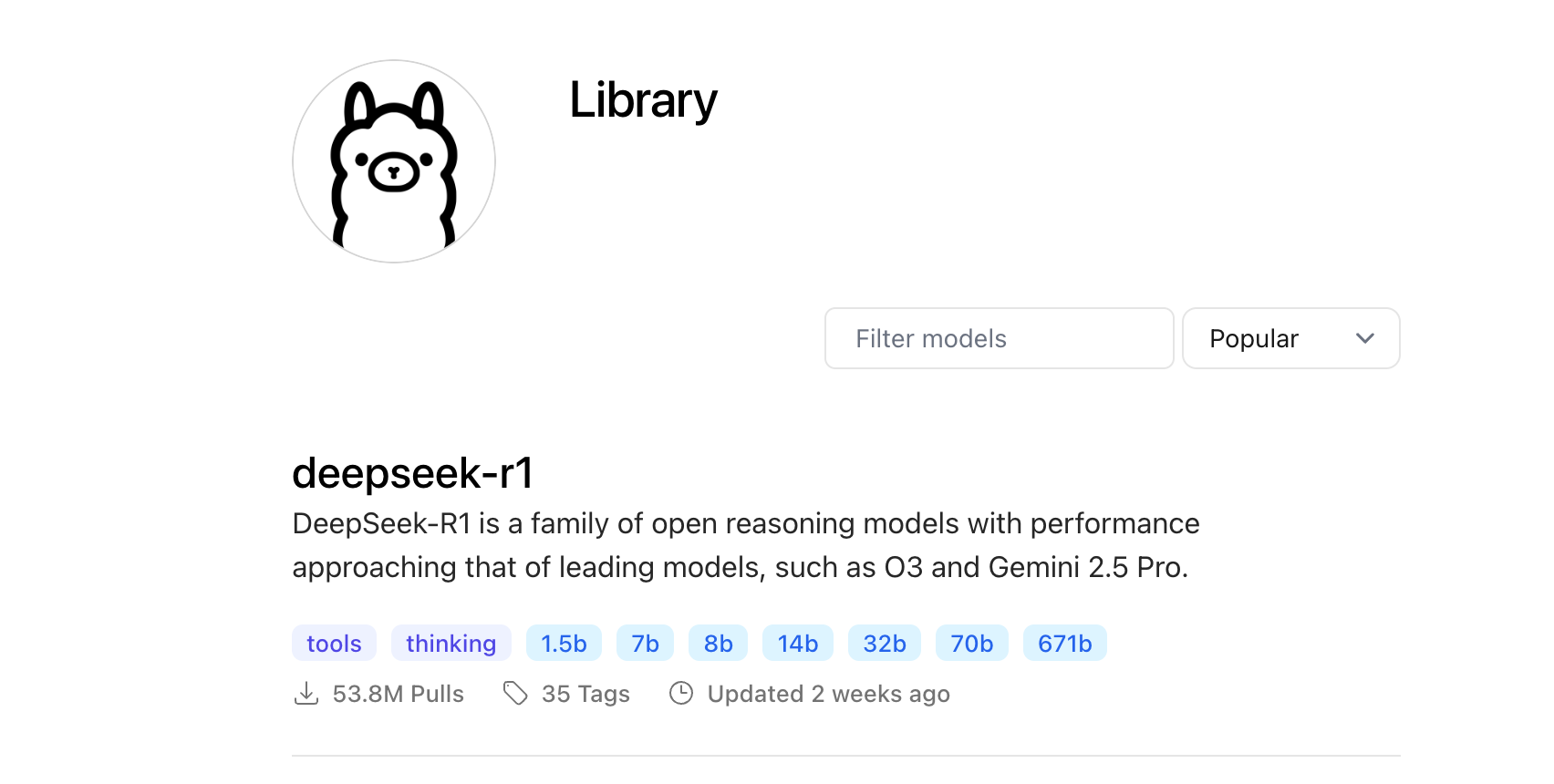
Step 2: Choose Your Model
Browse the Ollama Library to explore available models. For this walkthrough, I'll be running a Mistral model, but you can pick whatever model you want as long as your hardware can handle it. Check the model size to ensure it fits in your available memory—the library shows the requirements for each model.
Step 3: Load and Run
Copy the command from the Tags tab (it'll start with ollama run) and paste it into your terminal. The model will download and start running locally. Use /bye to exit when you're done.
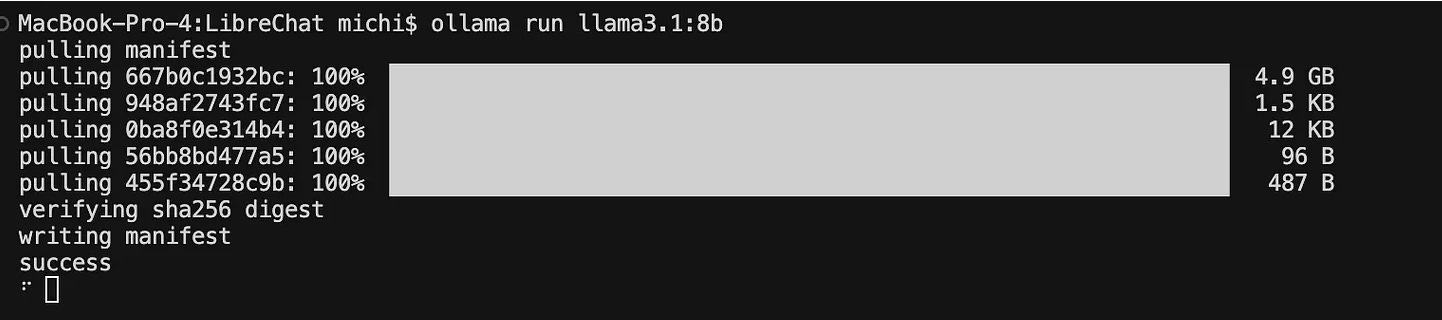
You can use it in the terminal like this:

In addition, you can also use your models in a self-hosted version of witheve.ai to enjoy Agent and workflow automations with access to over 1500+ apps (reach out for support). Below how I connected a llama and mistral model:
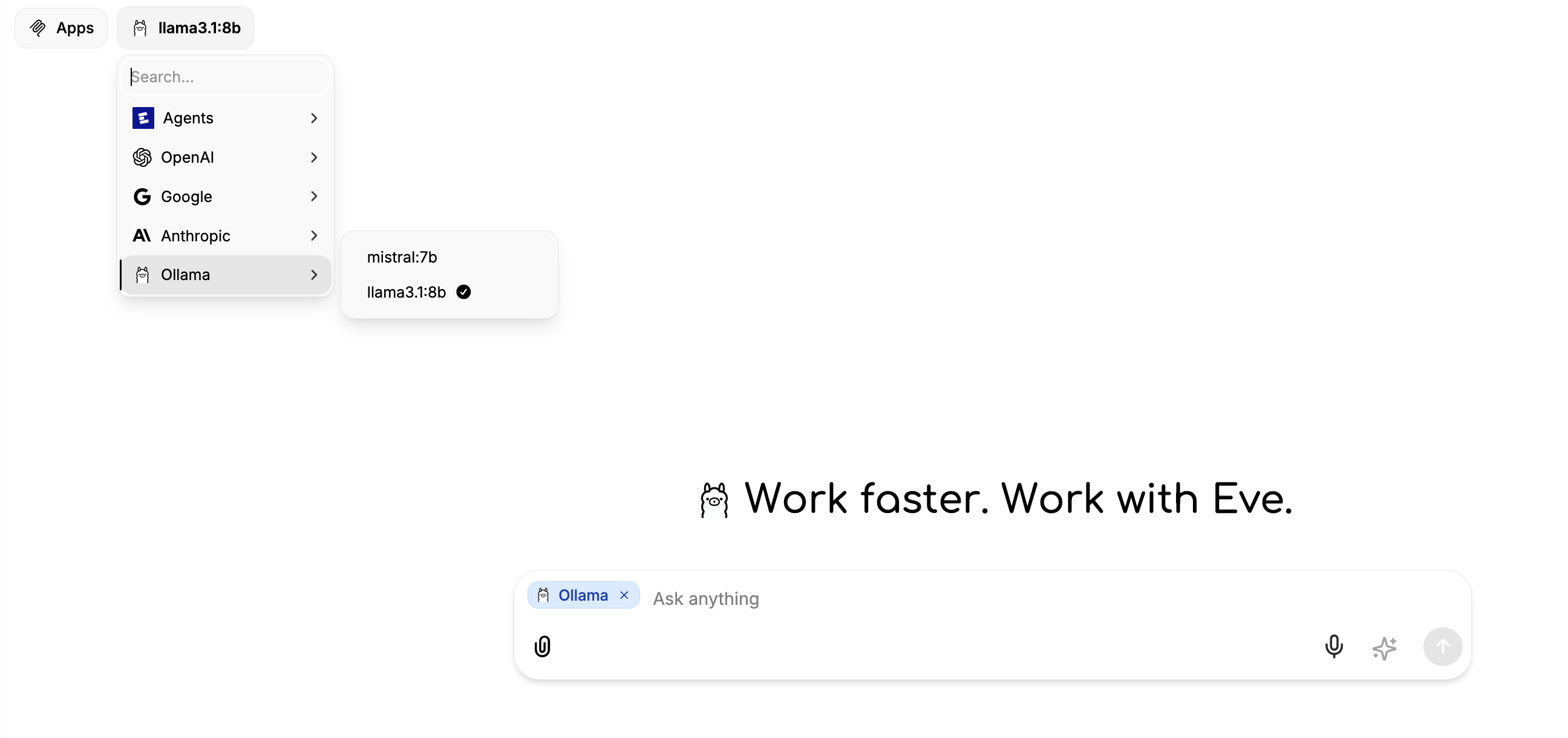
That's it. You now have a powerful AI model running entirely on your own hardware, with no cloud dependencies, no per-token costs, and complete control over your data.
Keep building,
Michiel